
To read the Medium version, press here.
This post presents a twitter sentiment analysis with the aim of better understanding what Brazilian tweeter users have to say about the ongoing process of pension reform (PEC 006-2019). Particularly, this blog covers i) data extraction and description, ii) Natural Language Processing (NLP) illustrations, and iii) Machine Learning (ML) classification models. The Python code follows the same structure and can be found here: https://github.com/AlvaroAltamiranoM/Sentiment-analysis-of-pension-reform
I guess the first question is why Brazil, and why Twitter? Well, the current pension reform in Brazil is quite important for the country’s public finance, as Brazil’s aging process will be a pretty rapid one (See next graph; and excuse me for the slight language schizophrenia within this text and within the code’s comments as well ¯\_(ツ)_/¯).
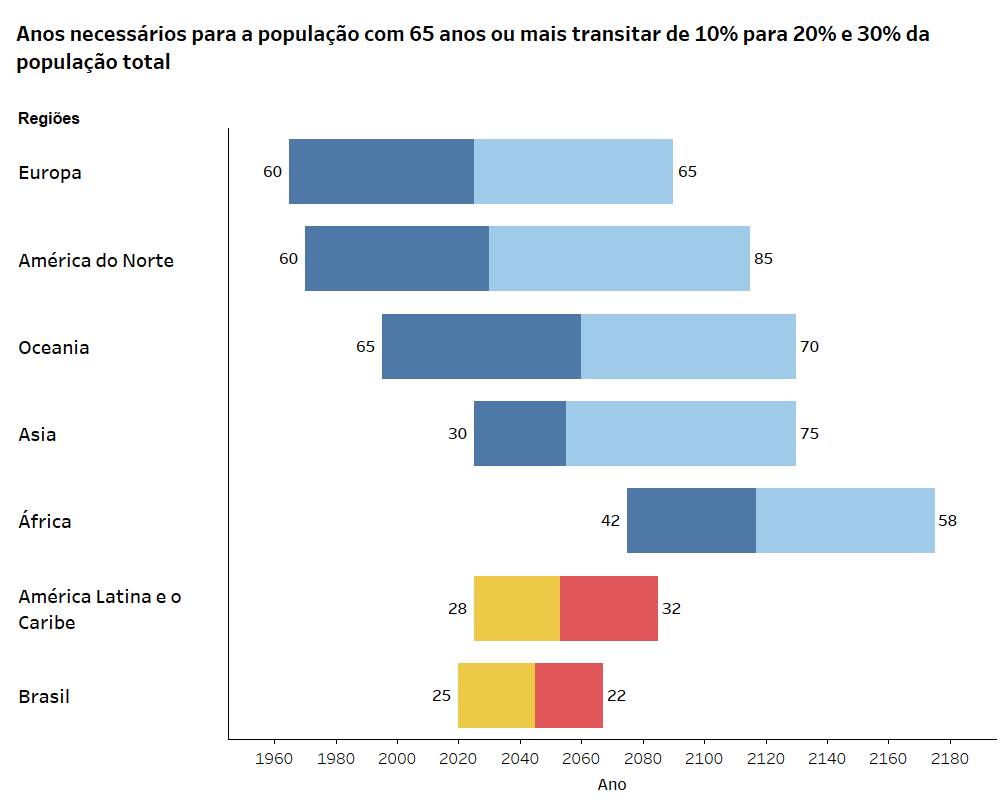
On the other hand, Twitter’s API allows to stream tweets from the last 7 days for free, and although its geo-location capabilities are not that good, you can select tweets in Portuguese from a particular topic of interest. In a few words, it’s a cheap way to collect opinions on specific topics. Finally, Brazil not only provides a good case study for the importance of its pension reform, but also because it is the only Portuguese speaking nation (I know of) currently reforming its pension system. At least it’s the only Latin American nation referring to Pensions as Aposentadorias, or Senior citizens as Pessoas Idosas.
I) Ok, so let’s query! The following snippet does the query, where the keywords are defined under the ‘query = ‘ object. Most of those keywords are variations of the following: Previdencia, Aposentadoria, Aposentados, reformaprevidencia, etc. That’s all the code we’ll see for now (as I said before, you can get the code in Github), from now on we’ll be discussing the main results.
# #Dates for fetching
start_date = '2019-7-9'
# # Create API object
api = connect_to_twitter_OAuth()
def get_save_tweets(INSS, api, query, max_tweets=200000, lang='pt'):
tweetCount = 0
#Open file and save tweets
with open(INSS, 'w') as f:
# Send the query
for tweet in tweepy.Cursor(api.search,q=query,lang=lang, since=start_date).items(max_tweets):
#Convert to JSON format
f.write(jsonpickle.encode(tweet._json, unpicklable=False) + '\n')
tweetCount += 1
#Display how many tweets we have collected
print("Downloaded {0} tweets".format(tweetCount))
query = '#Previdencia OR #Aposentadoria OR #Previdência OR #Aposentados OR Previdencia OR Previdência \
OR Aposentados OR Aposentadoria OR previdencia OR previdência OR reformaprevidencia OR #INSS OR #reformadaprevidência OR \
#reformaprevidencia OR #previdenciasocial -Filter:retweets'
# # Get those tweets
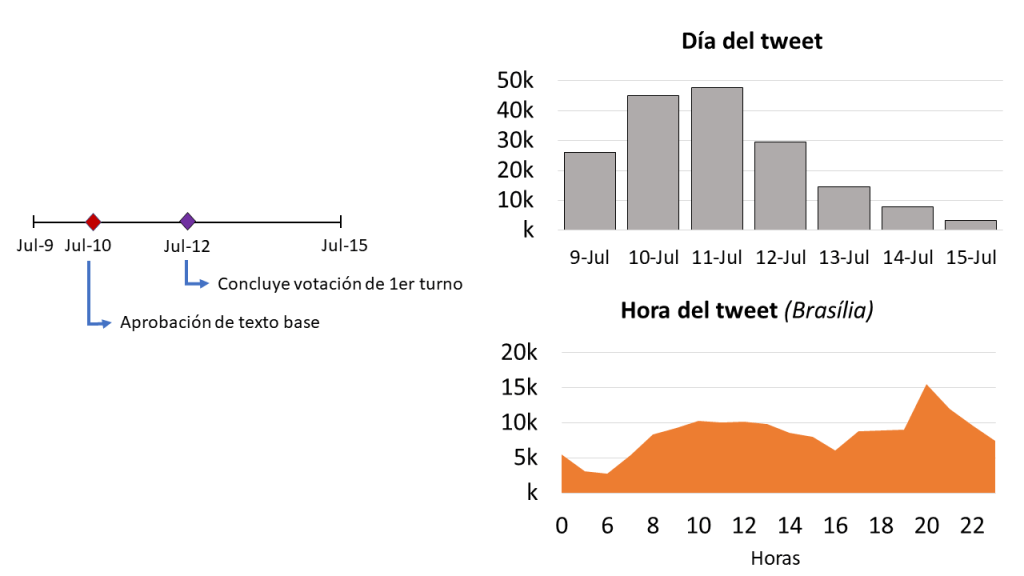
get_save_tweets('tweetsF.json', api, query)So, that code yields a json dataset including roughly 174 thousand tweets from the week of the first debate (-started on July 9th- to July 15th) of the reform’s proposal in the lower chamber of the legislative body (câmara dos deputados). Note: as the reform is a constitutional addendum it will have to go through 2 votes on that first instance and other two voting sessions on the Senate. The following graphs display our tweet’s timelines. This shows that the intensity of the tweets rose as the reform was discussed in the camara dos deputados, and declined as the base text was approved on the 10th and this first voting ended on the 12th. As for the time of day, people seem to be more active around lunch and after dinner. *With a broader stream listener we could see if these particular tweets are significant within Brazilian tweets at the time (out of our scope for now though).
In literary terms, the cleansed version of this corpus of tweets (about 16 million words) would fill up about 62 Don Quixote’s, or about 119 One Hundred Years of Solitude. The 500 most common words are represented in the following picture using Brazil’s map as a mask.

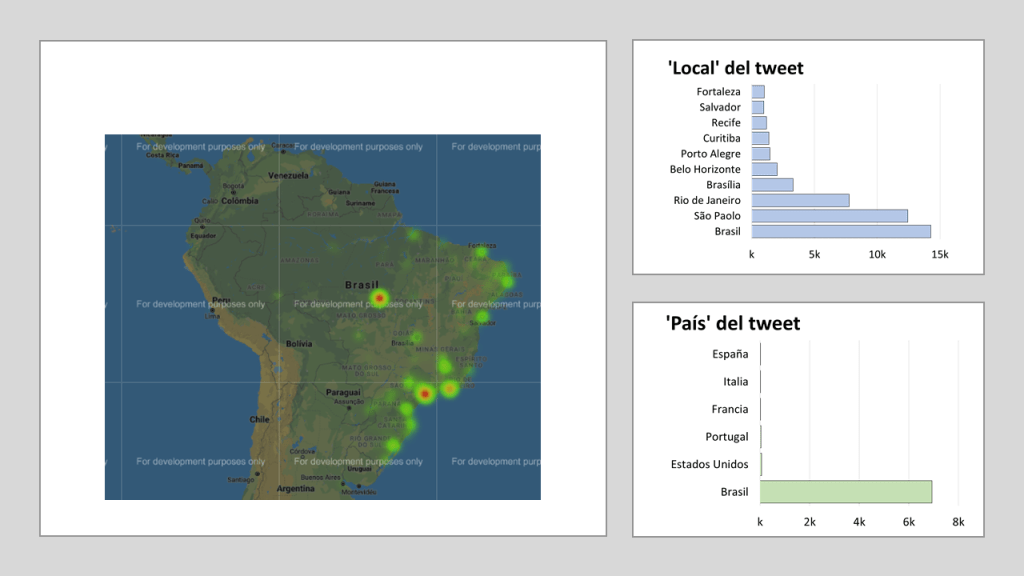
As mentioned before, Twitter’s geo-capabilities are limited, mostly because people do not usually share where they are tweeting from. Well, for those who do share, we are able to use Nominatin to translate location strings (eg. Belo Horizonte, Sao Paolo, etc.) into geocoordinates and do the following mapping. We can also see the distribution of locations and countries. That distribution seems to correspond with Brazil’s current demographic distribution, and may also correspond to Twitter activity in Brazil.
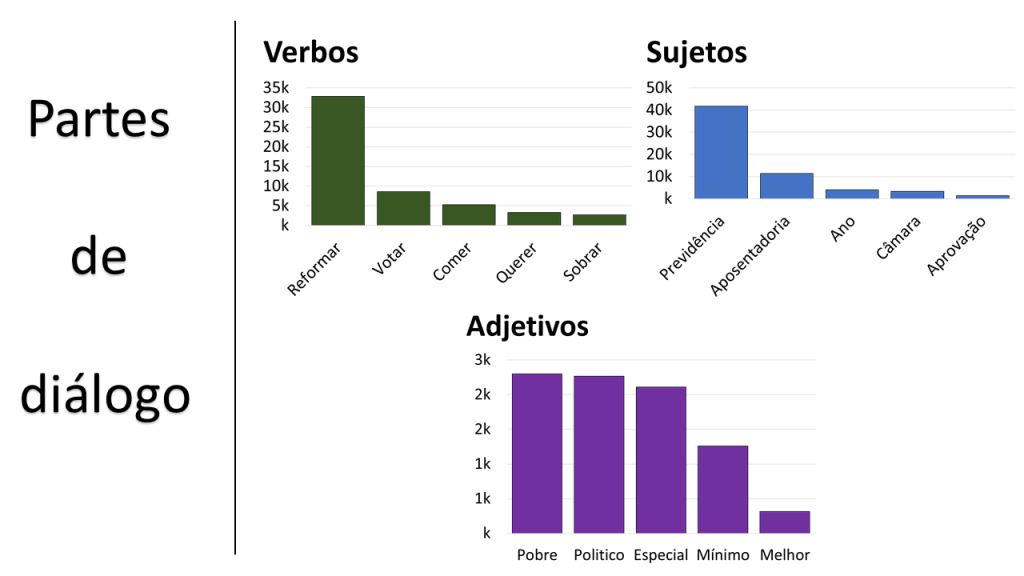
II) For the NLP part I’ll mostly use spaCy’s Portuguese CNN model (pt_core_news_sm), although I also use NLTK for some parts. Let’s see for example the most repeated Verbs, Nouns, and Subjects within our tweets (a.k.a Parts-Of-Speech). The usual suspects here, at least for the most common verbs and nouns. The most common adjectives, however, show that humans are still better at identifying POS, because the adjectives ‘Politico’, ‘Especial’, and ‘Mínimo’, actually refer to nouns in the context of this pension reform: they mean ‘Politicians’, ‘Special pensions’, and ‘Minimum wage or Minimum pensions’. I know this depends on how (over what) spaCy’s Portuguese model was trained, and that I could do some micro engineering about it, but still, there is no single model (yet) that gets every POS right.
Syntactic dependencies are other popular NLP illustrations using spaCy. The following two are examples of spaCy’s accuracy in regards to that matter.
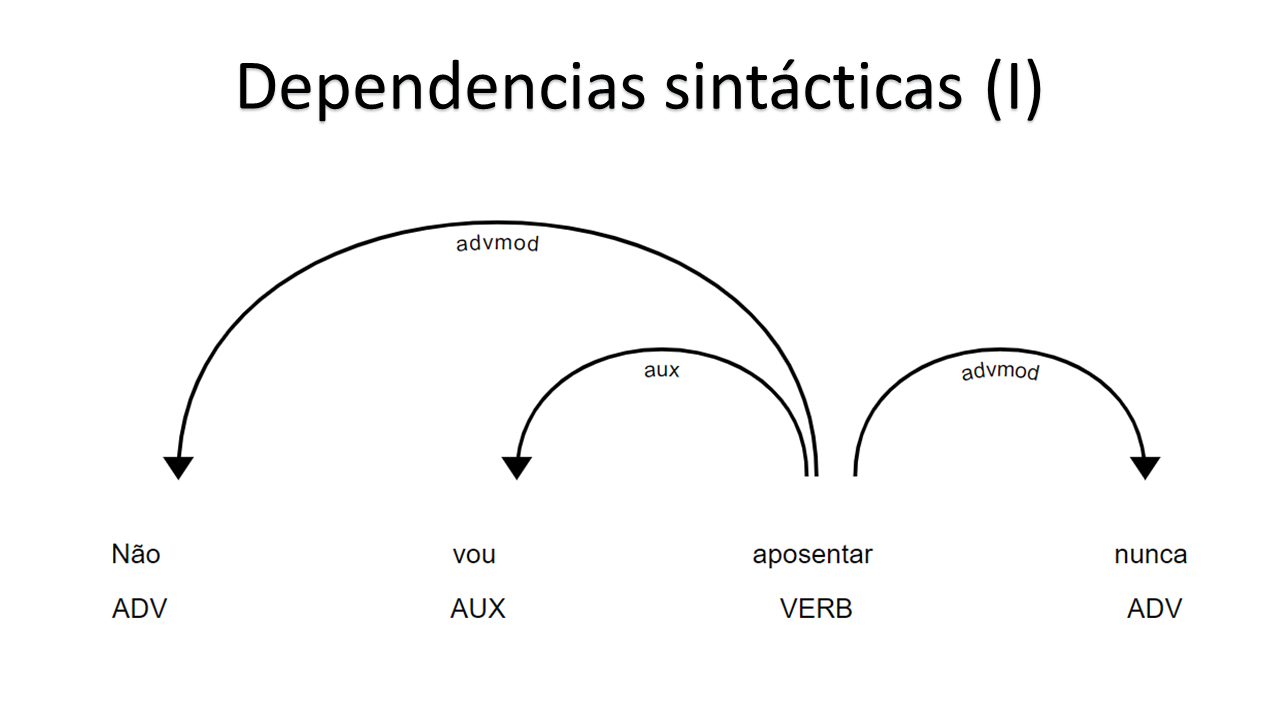
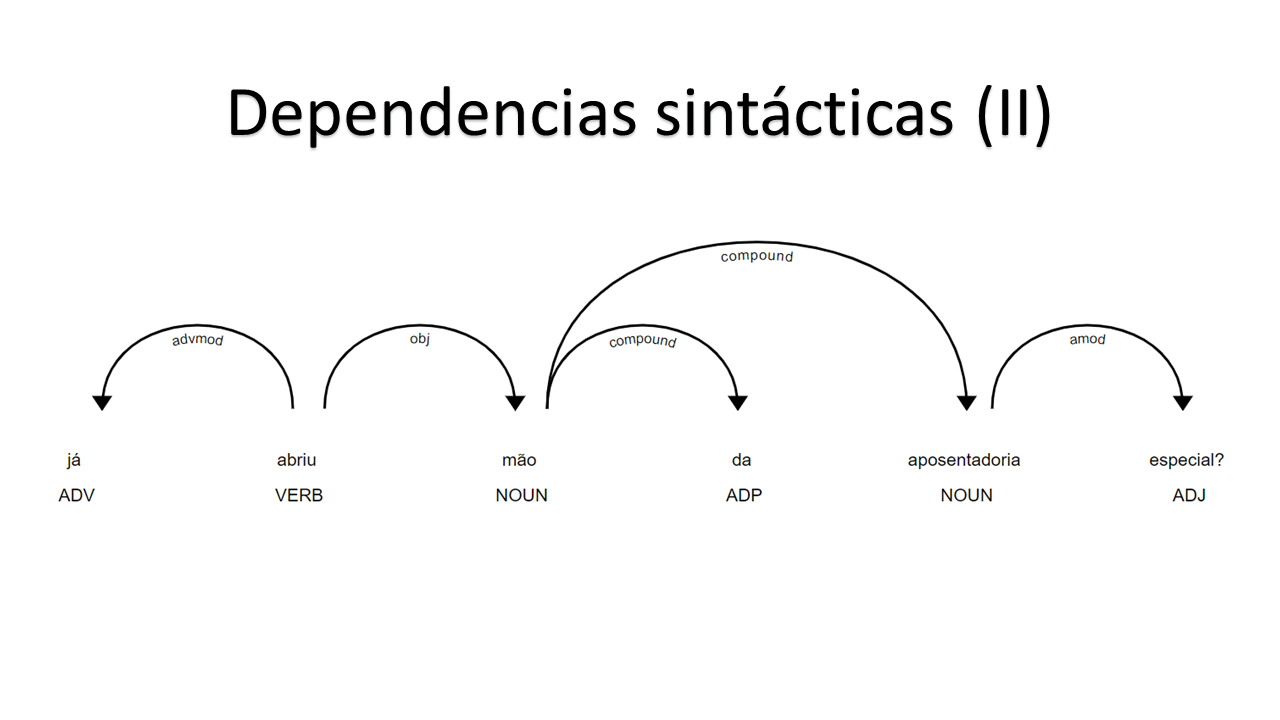
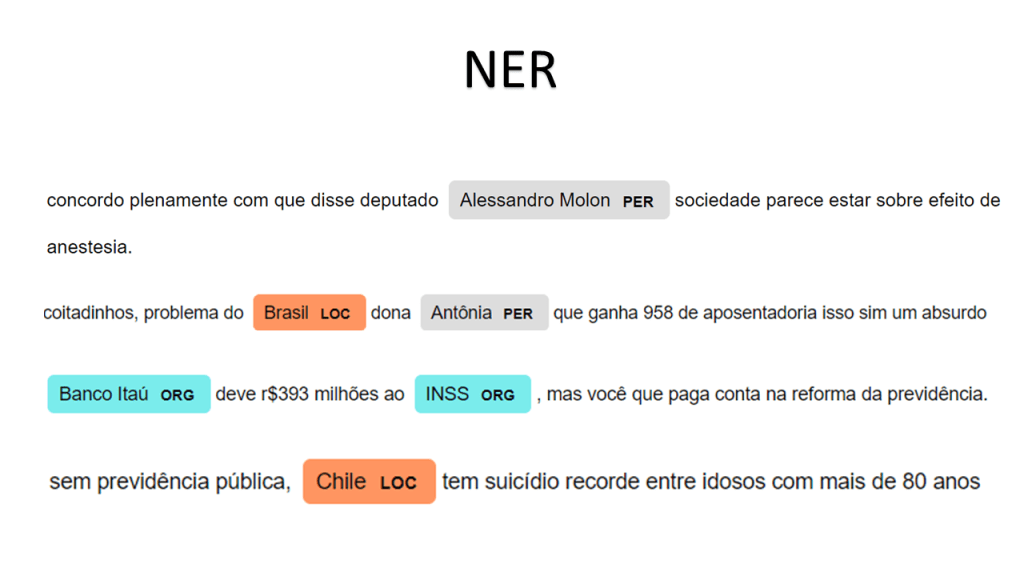
We can also do some Named-entity recognition (NER). The following examples show, for example, how spaCy’s model is good at recognizing that Alessandro Molon is a person, or that Brazil and Chile are locations.
Using another popular NLP library, NLTK, we can see the concordance of particular words. In this case we look for tweets with the word Idoso (meaning senior person).

III) In this part I present two supervised Machine Learning classification models and apply them to our ≈ 174k tweets. I use two annotated corpora for this task (both have a ternary classification: ‘negative-positive-neutral’). The first (Minas from now on) is a set of ≈ 9 thousand tweets about Minas Gerais’ government (Minas Gerais is a Brazilian state, a big one!). I found this first annotated corpora here: https://minerandodados.com.br/analise-de-sentimentos-twitter-como-fazer/
The second corpora consists of ≈53k opinion tweets about Brazilian TV shows (USP from now on), created using both expert manual annotation and semi-supervised learning. For details please refer to this corpora’s website (which includes links to the author’s Universidade de Sao Paulo thesis and derivative papers).
The pre-processing of text follows standard NLP procedures: general cleaning for html, xml, names, numbers, caps, etc.; portuguese stopwords; normalization (eg. lemmas); and tokenization (at the word level using spaCy’s tokenizer in the pipeline).
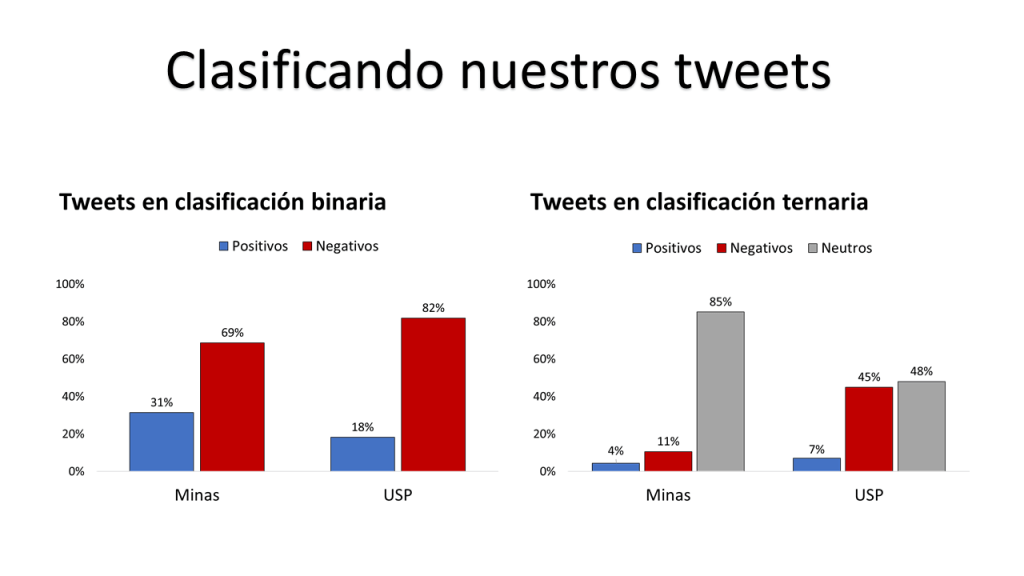
For the specific algorithm I use Multinomial Naive Bayes as it theoretically relates more to the assumption of independence among tokens (I also tried random forests, SVM and logistic classifications, all yield similar results in term of fitness). The training uses 75% of both corporas and the following precision estimates are displayed for both binary (excluding the ‘neutral’ class) and ternary (neutral, positive and negative tweets). I only display the ‘accuracy’ measure for parsimony, and because the recall and F1 measures do not differ greatly (you can replicate these results yourself). For people worried about the model’s ‘sentiment’ recognition capabilities, the accuracy measure is always close to the ‘recall’ indicator.
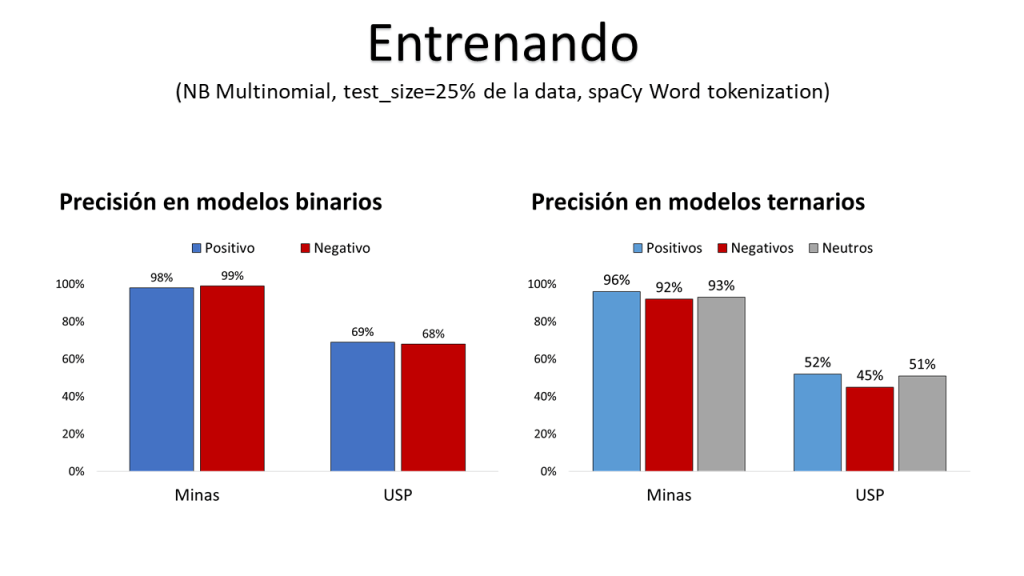
The Minas model yields better accuracy for both representations (possibly over-fitted though), and this is explained by the fact that this corpora is more ‘self-contained’ as it only relates to one topic (opinions regarding Minas Gerais’ goverment in 2017). The USP’s model, much bigger and more thematically disperse, yields lower accuracy estimates.
So, let’s apply those models to our ≈ 174k tweets! The figures ahead show the results. In general, our tweets are classified as being mostly negative (No news there!). When including the neutral class, the Minas model says our tweets are mainly neutral, and negative. USP’s model provides a balance between neutrality and negativity.
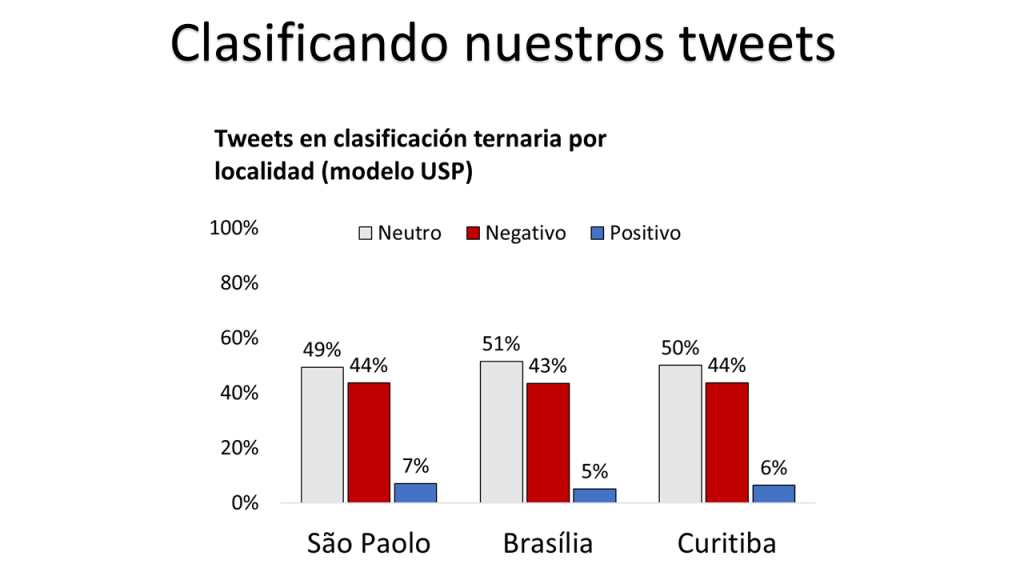
We could display such classifications by localities (cities). Here is the example using USP’s model:
What now? I guess we could reinforce these classification hiring some time in Amazon Mechanical Turk to apply reinforced learning and fine-tune these models. I won’t be doing that. What I’ll try next, however, is using some transfer learning with distilled BERT models provided by the PYtorch-spaCy recently created library. If someone else wants to come along in that path I would appreciate it. I also have some snippets (prototype) for livestreaming tweets that would allow for presque real-time classification, a sort of live opinion monitoring (this is not easy as twitter is strict about stream listeners).
Finally, some caveats/limitations and acknowledgements are needed. First, this type of twitter analysis lacks external validation (something household surveys or public polls also lack to some extend, but for which they provide better sampling/methodological documentation). Secondly, this project grew upon many other bloggers, programmers and coders. The list of which is too long to mention. I am but a code scavenger, and any errors are mine solely.
